Cotton farming sustains the livelihoods of nearly 100 million people globally, yet productivity is often threatened by pests, diseases, and erratic weather. Among these, pest infestations, especially from the Pink Bollworm (PBW), pose the greatest risk. PBW alone accounts for up to 70% of pest-related crop damage and has developed resistance to commonly used cotton varieties, making it increasingly difficult to control.
Despite widespread use of chemical pesticides, pest-related crop losses can reach up to 30% annually. Traditional pest control methods, like manual counting, are time-consuming, prone to error, and difficult to scale, often resulting in delayed or inefficient pesticide application. Inaccurate or untimely data not only affects yields but also increases health and environmental risks for farming communities.
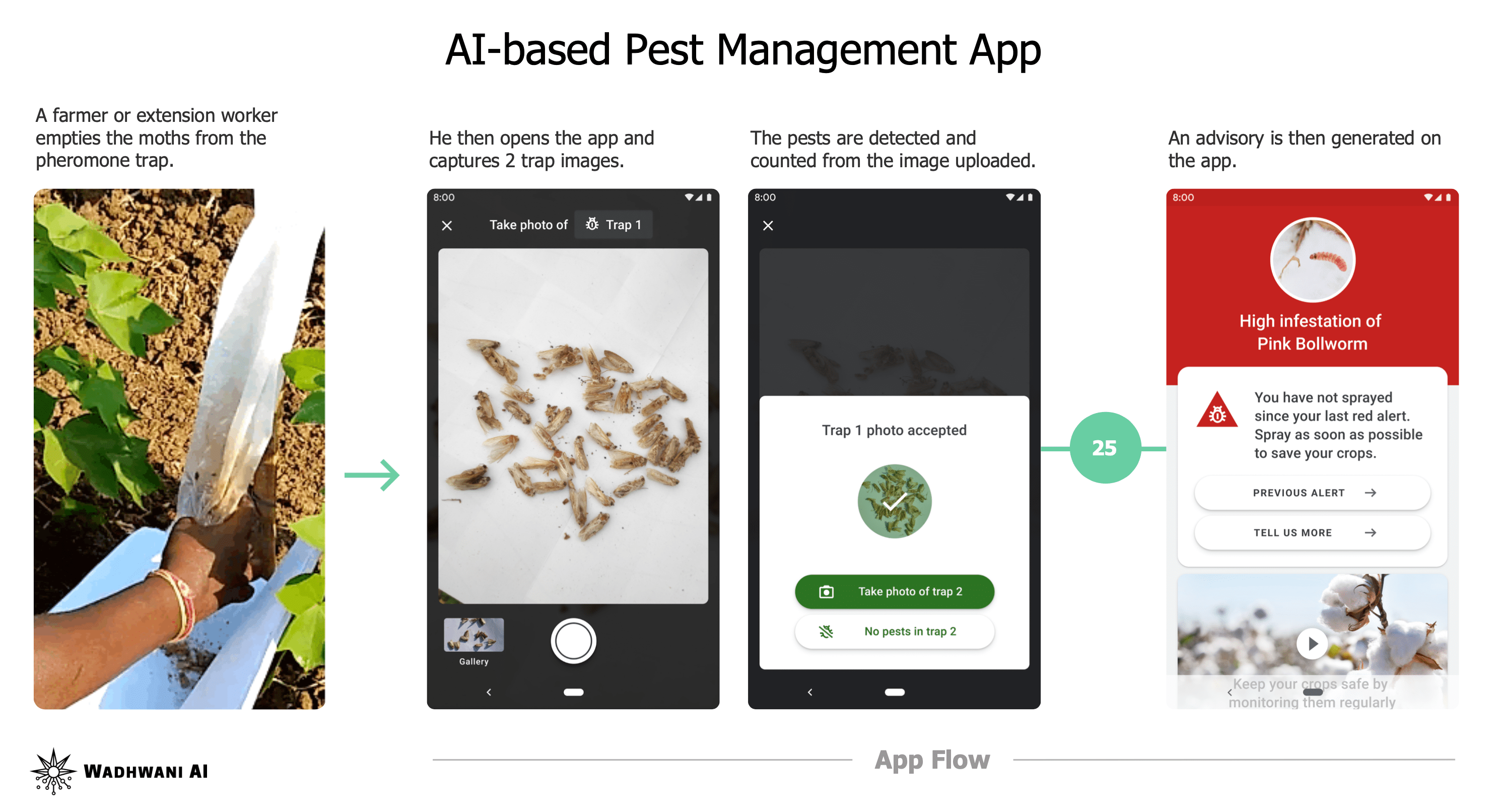
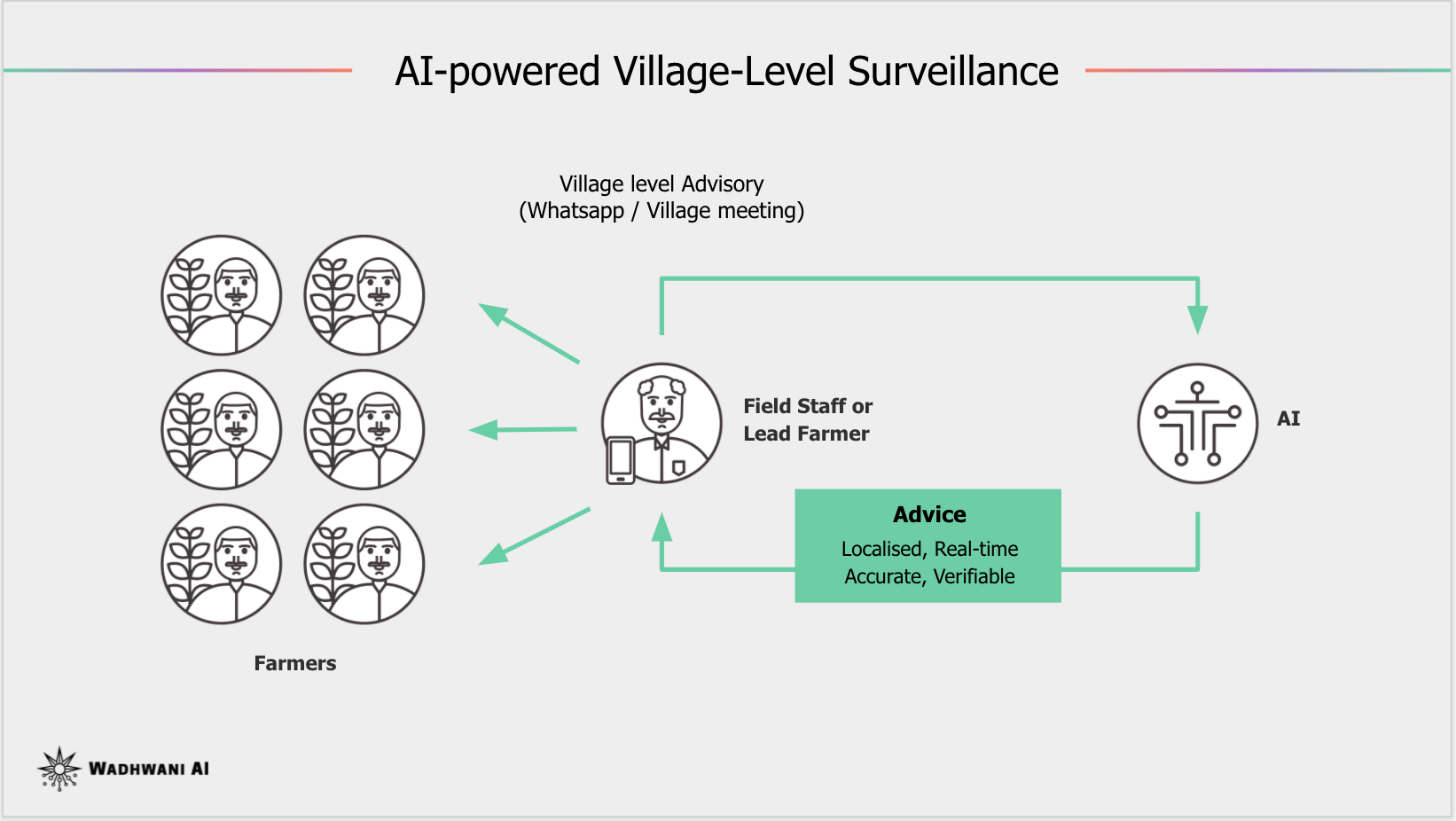
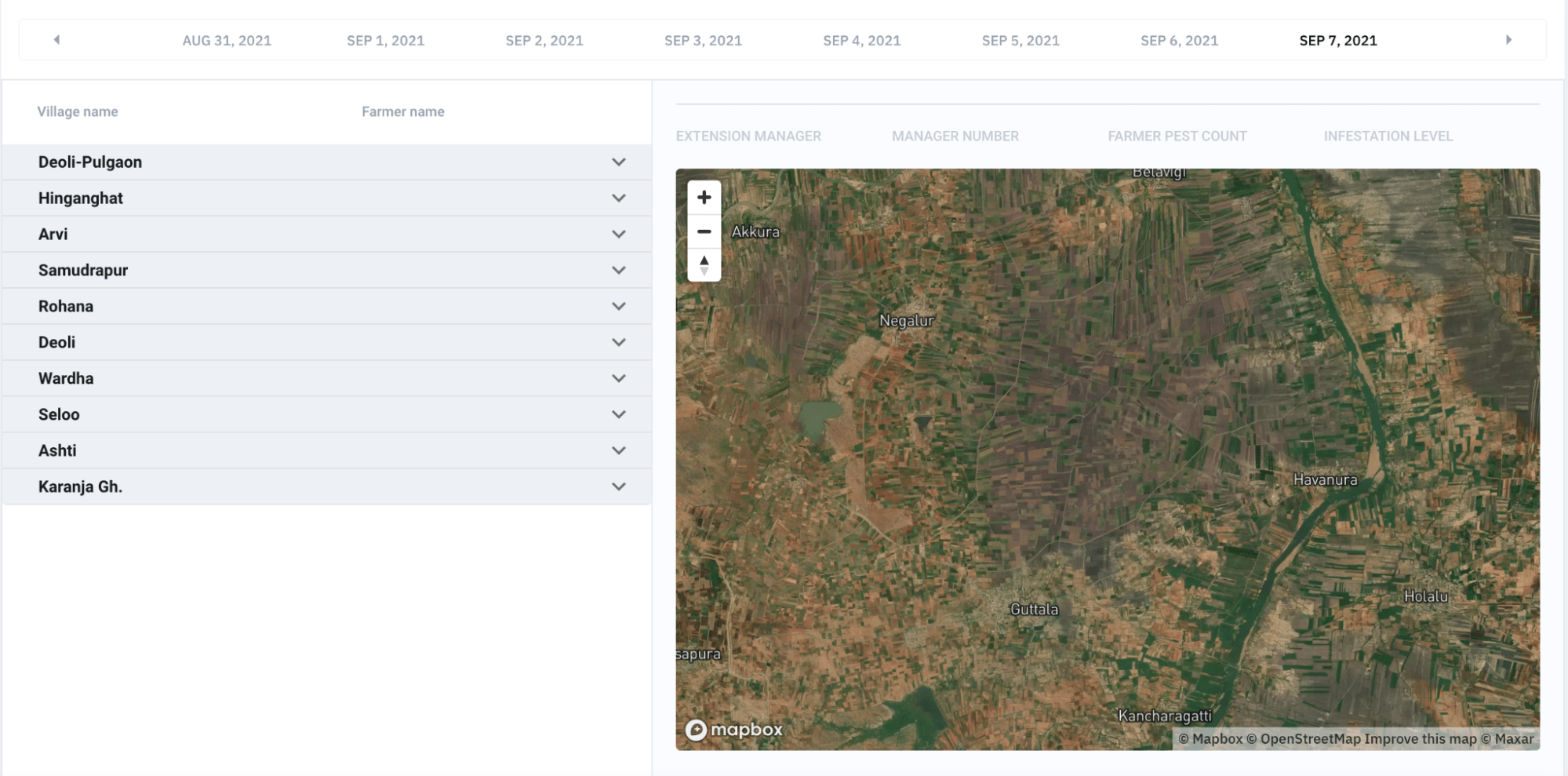
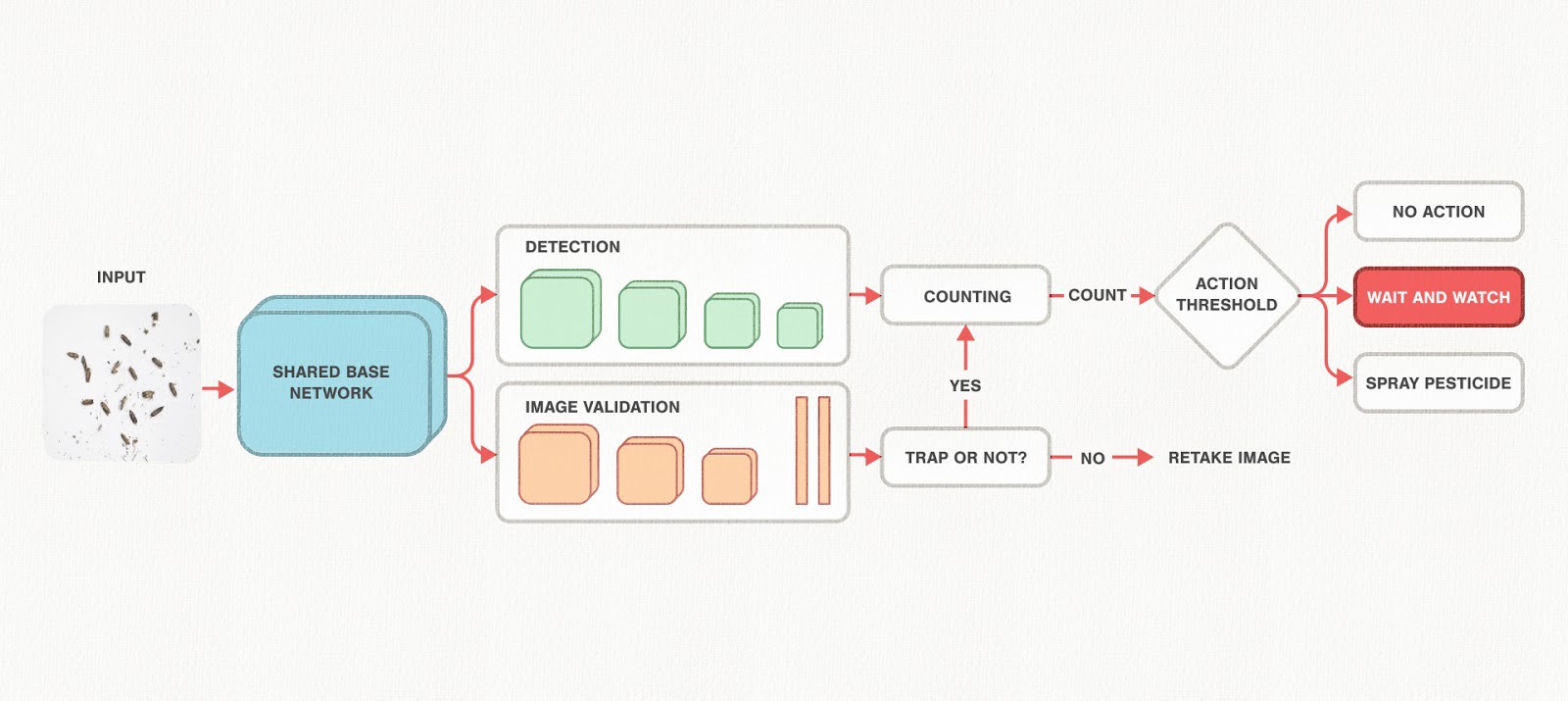
CottonAce addresses these challenges with an AI-powered early warning system accessible through a simple Android app. It enables timely, localized pest management decisions by identifying when and where spraying is necessary.