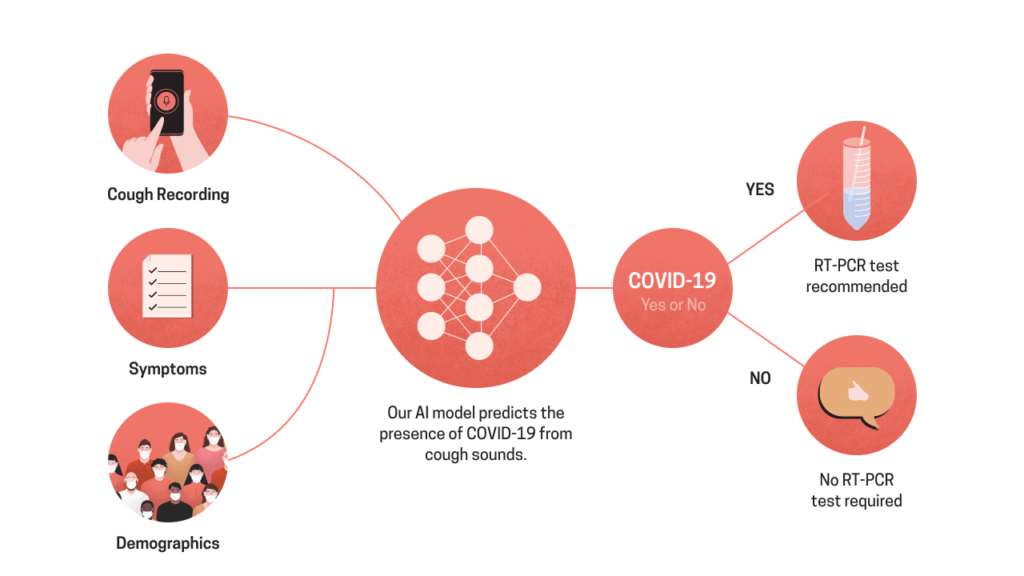
In early April, looking for ways to respond to the Covid pandemic, we turned our energies toward applying data science to address the evolving needs of administrators in mitigating the pandemic.
We used SEIR-like compartmental differential equation models to predict disease spread. The structure of these models was governed by the type of official case data made available to us by the Brihanmumbai Municipal Corporation (BMC) and the state government of Jharkhand.
The parameters of the model, including initial values for populations in some of the unobserved compartments, are fit to past data using a Mean Absolute Percent Error (MAPE) loss function. We apply machine learning principles in the parameter fitting process, using black box optimization methods, specifically Bayesian optimization methods such as hyperopt, to carry out the parameter sweep, and splitting time series population data into ‘training’, ‘validation’ and ‘test’ regimes. We developed a fast, robust, Approximate Bayesian Model Averaging (ABMA) method to estimate confidence intervals in epidemiological parameters and forecasts. In addition, we developed novel smoothing methods to attribute late reporting of cases to appropriate dates in the past.